Table of Contents
Introduction
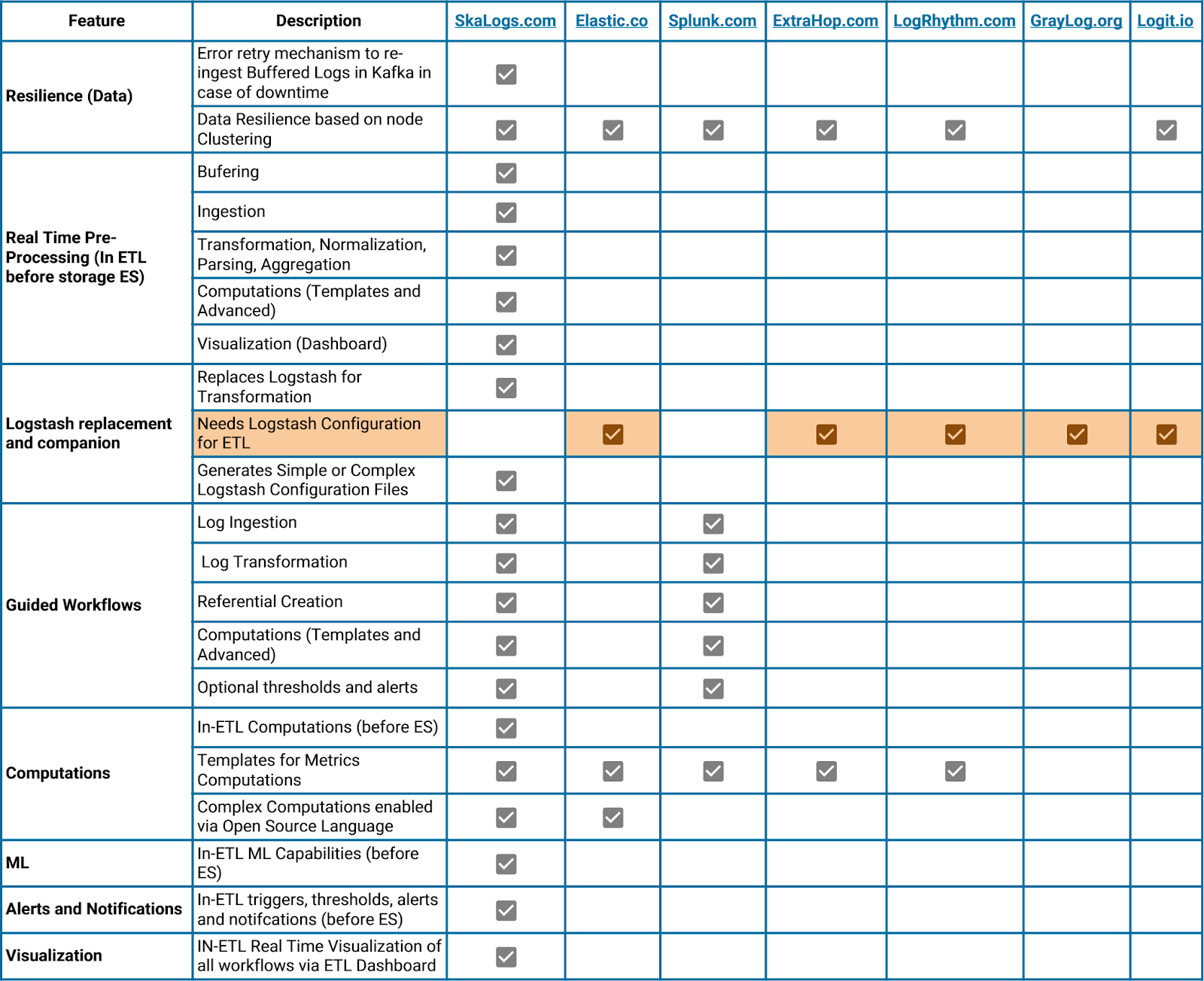
“SkaETL” is the 100% Java ETL developed entirely by SkaLogs. It is an innovative real-time ETL which allows the user to perform data (Logs) transformations using a set of guided workflows. It is one of the key elements of a successful Log Management project because it is usually one of the most complicated aspects to manage.


SkaETL provides multiple Log processing features which simplify the difficult work of log analytics:
- Workflows: Ingestion (“Consumer”), Metrics Process, Referentials
- Ingestion Process: workflow for defining ingestion process
- Parsing, Transformation, Normalization, Aggregation
- Validation, Filtering, Output (ES, HDFS, Notifications)
- Metric Process: workflow for calculation of Indicators and Metrics
- Uses Compute Templates (“SkaLogs Templates” ) for Standard calculations,
- Uses SkaLang, the SkaLogs proprietary Language (“SkaLogs Language”) for complex calculations
- Grok Parsing simulation
- Referentials: creating data referentials (repositories) for later reuse
- Preconfigured CMDB repository (directory)
- Event-Based Alerts and Notifications (Incidents, Thresholds): uses the Alert Module (“SkaLogs Alerts”)
- Storing processed Logs in Indexes in ElasticSearch, HDFS
Characteristics
No other Log Management solution (Open Source or Proprietary) provides an ETL like SkaLogs, whose characteristics are as follows :
- REAL TIME: real-time streaming, transformation, analysis, standardization, calculations and visualization of all your ingested and processed data
- GUIDED WORKFLOWS:
- Consumer processes: (data ingestion pipelines) to guide you through ingestion, parsing, transformation, filtering, validation, normalization
- avoid the tedious task of transforming different types of Logs via Logstash
- Optional metrics computations via simple functions or complex customized functions via SkaLogs Language
- Optional alerts and notifications
- Referentials creation for further reuse
- Consumer processes: (data ingestion pipelines) to guide you through ingestion, parsing, transformation, filtering, validation, normalization
- LOGSTASH CONFIGURATION GENERATOR: on the fly Logstash configuration generator
- PARSING: grok, nitro, cef, with simulation tool
- ERROR RETRY MECHANISM: automated mechanism for re-processing data ingestion errors
- REFERENTIALS: create referentials for further reuse
- CMDB: create IT inventory referential
- COMPUTATIONS (METRICS): precompute all your metrics before storing your results in ES (reduces the use of ES resources and the # ES licenses),
- SKALOGS LANGUAGE: Complex queries, event correlations (SIEM) and calculations, with an easy-to-use SQL-like language
- MONITORING – ALERTS: Real-time monitoring, alerts and notifications based on events and thresholds
- VISUALIZATION: dashboard to monitor in real-time all your ingestion processes, metrics, referentials, kafka live stream
Features
| TYPE | DESCRIPTION |
| SkaETL | Data Conversion Tool (Logs), Metric Calculation. Easily manage Variety and Log Variability. Adapt to any Industry and Business |
| Log Ingestion Pipelines | Create Log ingestion pipelines via guided workflow |
| Creating Log Repositories | Create data repositories from logs or external systems via guided workflow |
| Error Retry | Manage ingestion errors via an automatic retry mechanism |
| Real time | Visualize in real time the transformed data flow (Logs) (Kafka Stream) |
| Metric Calculation (excluding ES / Kibana) | Create simple or complicated (Non-ES / Kibana) metrics (using SkaLang proprietary Language). Reduces the impact on ES dedicated resources, thus reducing the number of ES Instances required |
| Alerts (thresholds) | Sending alerts when a user’s predefined threshold is exceeded |
| Alerts (anomaly detection) | Sending alerts in case of anomaly detection |
| Alerts (Machine Learning) | Discovery of known and unknown anomalies by Hybrid ML Methods (Supervised and 𐄂-Supervised / DNN) |
| Storage of Logged Data | Multiple and miscellaneous Data Silos: Allows to specify the output of the transformed Data in various Storage Infrastructure (ElasticSearch, Kafka, SysOut, Cassandra, MongoDb …) |
Guided WorkFlows
| TYPE | DESCRIPTION |
| Stream and Buffer | Log ingestion in the Kafka buffer |
| Log Processing | Transformation, Parsing, Normalisation |
| Log Ingestion | Create log ingestion pipelines |
| Error management | Resubmit ingestion errors via an automatic management mechanism |
| Referentials (repositories) | Create data repositories from Logs or external systems |
| Metrics | Calculate Metrics by simply defining them (thanks to templates) or by using a proprietary language that makes it easy to define a complex metric |
| Monitoring and Alerts | Perform monitoring, notifications and alerts |
| Visualisation | Visualize in real time the flow of transformed data (Kafka Stream) |
| Log output | Send transformed and metric data calculated in ElasticSearch (or other) |
Once the data and metrics calculated in the ETL, they can be sent in ElasticSearch (or other storage technology – NoSQL, SQL, Data Lake).
Comparison